
【第三章】誕生、サイバー空間に漂う巨大な頭脳

※この記事は2018年7月30日に投稿されたものです
どうも、キャッシュレス生活にハマり中のたけCです。
キャッシュレス生活にはじめてチャレンジしたのはもう10年以上前になる大学生時代です。
その頃でも十分にカードだけで生活できていた(学食がカードに対応していたことが大きい)のですが、使いすぎることがあまりに多くあったためその後は自粛することに。
そして10年の時を経て、東京に住むことになり改めてキャッシュレス生活を開始しています。そして今回の相棒はクレジットカードではなく、LINE PAYカード。仕組みはいわゆるデビットカードやプリペイドカードに近いものです。
とりあえずJCBがついているのでクレカが使える店舗では問題なく使える。やはり便利なのは「個人間送金ができる」という点。
これまでのキャッシュレス生活でもっともハードルが高かったのが、割り勘という場面。友人たちが現金ならば自分も現金で払わねばならないし、建て替えたとしてもお釣りとして現金が必要になってくる。そこでLINE PAYで割り勘できるとめっちゃ楽なんですよね。催促もしやすいし。
問題点はよく飲みに行く友人がLINE PAYを使っていないという点だけ。みんな使おう便利だから!
【連載企画】連載企画: AIの歴史を紐解く!
では本題です。
ただいま私のブログでは巷をもっとも賑わせているトレンドワードである『AI』(人工知能)についての連載を続けています。全7回のうち今日が4回目。折返し地点ですね。
もし初めから読みたい!という方は以下からどうぞ。
【序章】今さらだけどAI(人工知能)が怖いから歴史を紐解いてみる
【第一章】人間は、心を作れるのか?コンピュータの生みの親たち
【第二章】方針転換!人間を賢くしてくれる機械を作ろう
【第三章】誕生、サイバー空間に漂う巨大な頭脳 ←今ここ
前回の第二章までは、「人工知能とはコンピュータである」という答えをもとにコンピュータの歴史をお話しました。
・WWⅡを前後に「人間と同じように考える機械」を作りたいと願った3人の生みの親。
・「人工知能(Artifical Inteligence)」という言葉を生んだダートマス会議。
・機械自体が賢くなるのではなく、人間を賢くするための機械として進化したパーソナルコンピュータ。
・小型化すればするほど高性能となることを予見したムーアの法則。
しかし、どれだけコンピュータが高性能になろうとも人工知能の実現は夢のまた夢のままでした。
一体なにが足りないのか?計算能力が高いだけでは人工知能になれないコンピュータが、なぜ2018年現在には人工知能として働き始めているのか?この数十年の間にどんな技術革新があったのか?
AIの歴史は新たな局面に突入します。
目次
・高性能なパソコンは、暗算が早いだけの幼稚園児
・インターネットは50年以上前に誕生しました。
・ウェブとは、インターネット上にある巨大な街のことです。
・壁を超えよ、進撃せよ、サイバー空間の巨人Google
・新時代のバベルの塔。私たちはまたひとつになれるのか。
高性能なパソコンは、暗算が早いだけの幼稚園児
人工知能、つまりは「人間と同じように考える機械」を作るためには一体何が必要なのでしょうか?
ひとつは処理能力の高いコンピュータです。処理能力が高い、をもっとわかりやすく言い換えると計算を処理するスピードが早いということです。
パソコン"だけ"では情報を、作れない。集められない。
ここでぜひ思い出してほしいのですが、第一章でブール代数という理論をご紹介しました。
カンタンに説明すると、ブール代数とは人間の論理的な思考はすべて計算によって導き出させる、という理論です。そしてブール代数をもとに電子制御によって論理的思考を機械でも実現したのがデジタル情報です。
今、私たちの生活の中でデジタル情報はなくてはならないものです。
スマホから聞くオリコン1位の音楽も、
パソコンで編集する新商品の企画書も、
暇つぶしに見るヒカキンのYouTubeも、
私たちが日々の生活の中で接する情報という情報がデジタル化しています。
つまり、私たちが日々得ているデジタル情報は膨大な計算が繰り返されていることによってコピーされているし、アレンジされているし、伝達されているのです。
コンピュータが大量の情報を扱えるように高性能になったからこそ実現した世界です。
しかしながら計算能力が高いだけのコンピュータでは情報を生み出すことができません。いや、生み出すどころか情報を集めることさえもできません。
一人の人間では限界がある。その限界を突破するには・・・
高性能なパソコンを使いこなすには、十分に情報を知っている人間が必要ですよね。操作する人間がいなければ、パソコンだけでできることには限りがある。
これは人工知能を実現するためには避けては通れない難題です。人と同じように考える機械をつくるのであれば、人の力を借りなくても情報を生み出せる必要があるからです。
そこで必要になってくるのが、人工知能に欠かせないピースの2つ目の「膨大なデータ」です。
パソコンだけでは知りえない情報は人から得るしかありません。しかし人間一人が持っている情報には限りがあります。もし人間一人ではなく、百人、千人が持つ情報を手に入れることができたら?もし世界中の人間が持っている情報をコンピュータが知ることが出来たら?
それは完全ではないけど、かなり人工知能と呼べるものに近づけると思いませんか?
すでにお気づきの方もいるかもしれません。
そう、人工知能が実現するために必要な「膨大なデータ」を集める仕組みはすでに出来上がっています。それがインターネットです。

個人的にもっとも好きなAI映画『アイ・ロボット』
インターネットは50年以上前に誕生しました。
世の中にある発明の多くが戦争をきっかけに開発されたり、進化したりしています。もちろんインターネットも戦争がきっかけで・・・というのはよくある間違いですので気をつけてください。
確かにインターネットの開発にあたってはアメリカ国防省の予算が割かれていたことは事実ですが、その目的はもっぱら学術目的。先進的な研究を進めていた大学同士で情報のやりとりをするために開発されたのインターネットです。
パケット通信ですぐにつながるネットになる
1963年、アメリカにある4つの大学の研究所にあるコンピュータを相互に接続する実験が行われました。『銀河間ネットワーク』と呼ばれるこの実験がインターネットの原型です。
この実験ではある大きな課題が浮かび上がりました。それは糸電話をつなぐかのようにネット回線を張り巡らせると、非常に多くの回線をコンピュータごとに準備しなければならない問題。
少し想像してみてください。
あなたが友人たち3人(合計4人)と糸電話を使って会話をしようとしたら・・・あなたは何個の糸電話をもって話をしないといけませんか?そう3個です。さらに5人、10人と話す相手が増えていけば、その数の分だけ糸電話をもつ必要があります。
さらに、あなたが友人Aと会話しているとき、友人Bがあなたと話すことはできません。たとえ一言だけを伝えようとしても、長い友人Aとの会話が終了しない限り、友人Bと言葉を交わすことができないのです。
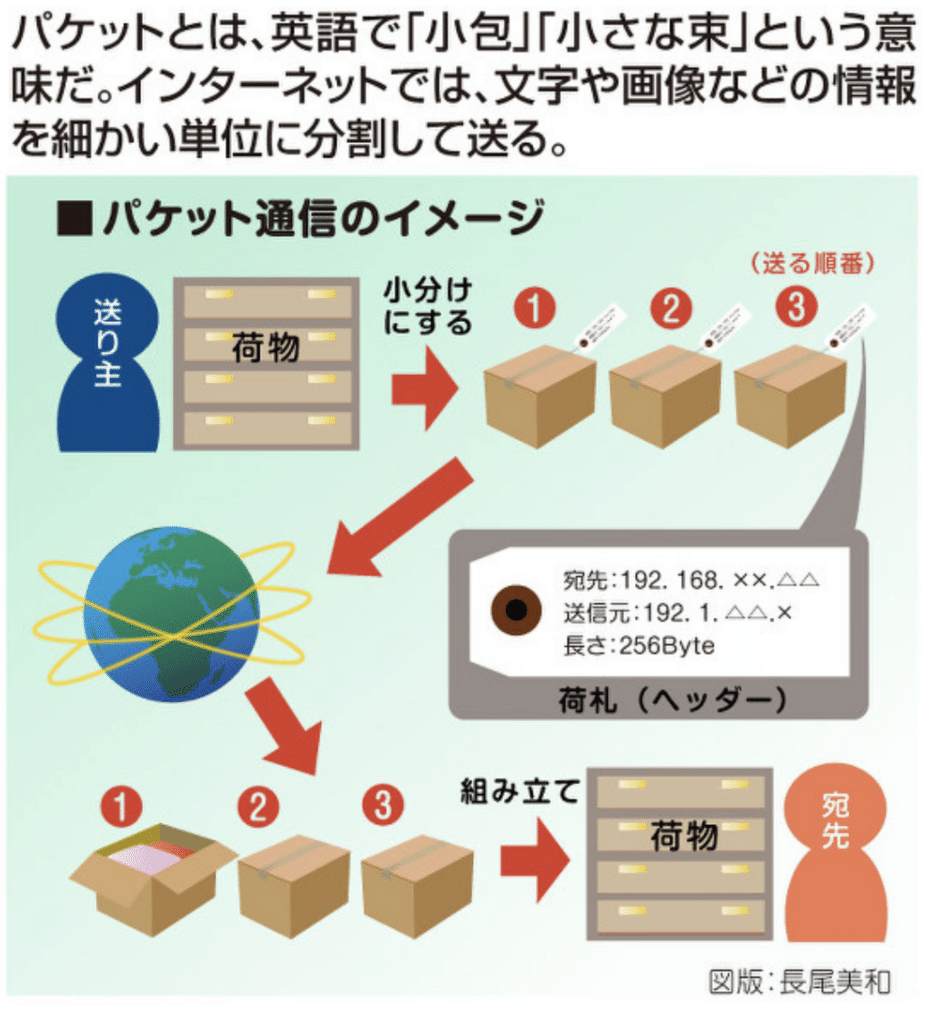
たった4台のコンピュータをつなぐだけでも、このように自由に通信することができない問題が起きてしまった銀河間ネットワーク。この問題を解決した方法がパケット通信です。携帯電話のプランにも「パケ放題」というのがありますよね、このパケのことです。
パケット通信についての解説はそれだけで大学の講義のようになってしまうので、カンタンな説明に届けておきましょう。
パケットとは「小包」のこと。荷物を一つの大きなダンボールに入れて配達するのではなく、小さなダンボールに分けて配達して後から組み立てるように情報を伝達するのがパケット通信です。
従来の通信は大きな荷物を一度に送るようなものでしたので、それを配達している間は他の荷物を運ぶことができなかった。一方でパケット通信では小包にして分けて送るので、他の荷物と同時に届けるということが可能になりました。
さらに、従来の方式ではもし一部でも壊れたデータを送ってしまったら、改めて1から送り直しが必要でしたが。が、パケット通信では壊れたパーツのデータだけを送り直せば済むので、通信状況が安定しない相手にも大容量のデータ(画像や音など)を送ることができるようになったのです。
https://mainichi.jp/articles/20160416/mul/00m/300/00900scより引用
『不都合な真実』の議員、大活躍!
2006年に公開された地球の環境問題に切り込んだ映画『不都合な真実』を覚えていませんか?当時のアメリカ副大統領であったアル・ゴア氏が主演した映画ですね。
このアル・ゴア、実はインターネットの普及に大きく貢献した議員でもあります。
インターネットが民間開放されたのは1992年。それまで多くの税金を費やし学術目的に限定されて使われていたインターネットですが、ついに商業目的での利用が可能になりました。
その前年、1991年はソ連が崩壊した年であり、まさに世界にグローバリゼーションの波が広がるその瞬間でした。
民間開放にさきがけて、アル・ゴア上院議員(当時)はインターネットをより多くの研究機関のコンピュータと接続できるようにと、6000万ドル(当時の日本円で8億円)の予算をつけることを働きかけました。この予算というのが国防省のものであったため、インターネットは軍事技術であるかのうように言われていますが、実際にはもっと前からインターネットは産声をあげ学術研究の分野で育っていたのです。
インターネットは情報を集めるインフラです。道路が到るところに行き渡り、人々の交流が盛んになることで街が作られていったように、インターネットが世界中に広まることで情報の交流が盛んになることで、ネット上にも街が生まれていきました。それが今、私たちの知識の泉であるウェブ(WWW)です。
ウェブとは、インターネット上にある巨大な街のことです。
もしかすると、「インターネット」と「ウェブ」の2つを同じであると思っている人がいるかもしれません。
おおざっぱに言えば同じように捉えて問題ないのですが、ここではあえて区別して正しい知識を知っておきましょう。
インターネットとはインフラのこと。例えるなら道路です。電気や水道とも例えていいのですが、デジタル空間にある道路と捉えていただくことが分かりやすいと思います。
ウェブとは、いわゆるホームページのことであり、ホーブページの集まりのことでもあります。例えるならビルや街です。インターネットという道路が地球上を行き交っていて、その各所に点在している街のことをウェブと言います。
さて、インターネットができただけでは人工知能に必要な情報は得られません。なぜならインフラ(道路)なので、情報は通過していくだけで貯まっていかないからです。そこで情報を貯めていく場所としてウェブが開発されました。
分からないことは、「聞く」よりも「調べる」文化が始まった
ウェブ、正確には「ワールド・ワイド・ウェブ」(World Wide Web)の生みの親はティム・バーナーズ=リーです。
彼はスイスの素粒子物理学研究所CERN(ケルン)で働いていました。
ケルン、どこかで聞いたことはありませんか?そう重さの原因であるヒッグス粒子を発見したあのケルン研究所です。理論上は存在するとされていた幻のヒッグス粒子の存在を初めて確認できたあのニュースには本当に興奮しましたね。
そんな最先端、かつ専門的な研究所にいたティム・バーナーズ=リーは、他の専門家が研究している内容をいつでも確認できる仕組みづくりを始めました。物理学の研究は非常に細分化が進んだ学問であったため、どんなに優秀な研究者であっても自分の専門から少しでも外れた事に関する研究は、その専門家に尋ねるほか方法がありませんでした。
しかし、そんな最先端の研究に勤しんでいる人たちに分からないことがあるたびに直接聞いていたのでは、お互いに研究を進める時間をとることができません。
そこで専門家それぞれが持っている最新の研究結果や論文を、インターネットを介して閲覧できるようにするとより効率よく研究が進むのではないか。とティム・バーナーズ=リーは考えたのです。
ウェブとは、"くも"の巣ではなく、脳の神経"網"のこと
こうしてティムは世界初のWEBサイトを作成し、インターネット上に公開しました。
この時に現在のウェブを形作る様々な発明がされました。
たとえば、リンクという仕組み。
論文には引用という形で他の論文を参照している部分が必ずあります。これと同じような仕組みをウェブ上の文書にも組み込んだのがリンクです。そしてこのリンク機能をもった文書構造をHTMLと名付けました。
興味深いことにリンクという仕組みは、リンクしている側からはどのWEBサイトをリンクしているかを知ることはできますが、反対にリンクされている側からはどのWEBサイトからリンクされているのかを知るようには作られませんでした。
これは人の脳神経の仕組みと同じようになっており、ティムは意識してこのような仕組みにしたと言っています。

世界初のWEBサイト。当時のブラウザでは文字とリンクしか見れなかった。
ネットにあるものが無料になってしまう、そのキッカケ
ティムが発明したのはWEBサイトだけではありません。WEBサイトを閲覧するためのソフト「ブラウザ」も開発しました。
少々話はそれますが、「ネット上にある情報に値段がつかない。無料ばかりだ。」ということが度々話題になりますよね。実はこのネット上にあるものは無料、というきっかけになったのがティム・バーナーズ=リーのブラウザだと私は考えています。
というのも、ティムはWEBサイトを閲覧するためのブラウザソフトを無料で公開し、誰でも使えるようにしました。それだけでなく、ブラウザのソースコード(プログラミングの設計図)までも無料で公開してしまったのです。
当時ではまだ誰も開発していないソフトであり、独占すればこれから大儲けができたかもしれないソフトを設計図ごと無料で公開してしまいました。が、そのおかげでブラウザの開発は一気に熱を帯び、『モザイク』や『ネットスケープ』といったより高機能なブラウザが次々と開発され、世の中のWEBサイトは加速度的に増えていきました。
道路となるインターネットが民間に開放され、情報を貯めていつでも自由に見ることができる街となるウェブがこうして誕生しました。かなり今の私たちの生活に近づいてきたのではないでしょうか?
そしてついにインターネット、ウェブの世界を蹂躙するあの巨人が誕生します。
壁を超えよ、進撃せよ、サイバー空間の巨人Google
世界で初めてWEBサイトが作成されたのが1990年。それからはインターネット上には加速度的にWEBサイトが増えていきました。
1995年: 2万サイト
2006年: 1億サイト
2014年: 10億サイト
2018年: 18億サイト
こうして多くの情報がウェブ上に蓄積されていくにあたり、私たちが知りたい情報を探し当てることも徐々に難しくなってきました、、、ということはなく、私たちは何かを「調べたい!」と思ったやいなや、水が欲しければ水道の蛇口をひねるかの如く、分からないことがあればネットで検索するようになりました。
今、世界の検索サービスの覇権を握っているのが、そうGoogleです。
Googleはどのように検索結果を決めているのか
Googleの二人の創業者、ラリー・ペイジとセルゲイ・ブリン。二人はスタンフォード大学の博士課程をおさめる過程でGoogleを創業したことは有名な話ですよね。
Googleの創業は1998年。当然ながら、それよりも以前からウェブ上には検索エンジンはありました。
検索エンジンとは、何か調べたいことがあればそのキーワードを検索窓に入力することで、何億とあるWEBサイトの中から目的の情報が書いてあるページをいくつか選んでくれるというもの。
しかし当時の検索エンジンは非常に精度が悪く、カンタンに言えばページ内に多くの「検索キーワード」が書かれていれば上位表示されていました。例えば、ラリーとセルゲイの二人が検索エンジンを使って「スタンフォード大学」について調べた時、検索結果の一番上にはスタンフォード大学のHPではなく、スタンフォードという名前を使ったポルノサイトが上位表示されていたほどに。
そこで二人は博士課程の研究として検索エンジンの開発に乗り出しました。彼らが考えた検索エンジンの仕組みは現在でも基本は変わっていません。
ポイントはリンクです。
ティム・バーナーズ=リーが発明したリンクという仕組みは、論文の引用を参考に作られました。論文は引用されている数が多ければ多いほどに、間違いがなく価値が高い情報であると言えます。
同様に、WEBサイトもリンクされている数が多ければ多いほどに、その情報は間違いが少なく信用できる。
だからGoogleはWEBサイトのリンクをたどって、WEBサイトそれぞれに点数をつけることによってより正確な(検索している人が求めている)情報が掲載されているWEBサイトを上位表示する検索エンジンを作ったのです。

創業当時の2人。大学のガレージからスタートした。
検索エンジンは人工知能を持つべきだ。
Google創業者の二人はそれぞれに創業当初からこのような発言をしています。
ラリー・ペイジ
「グーグルはかしこいだけでなく、世界の全てを理解する、人工知能になる必要がある」
セルゲイ・ブリン
「ユーザーが質問を考えるのと同時に、答えを返すようになる」
こうした考えを持っていたからだと思いますが、Googleは検索エンジンにとどまらず様々なサービスを世の中に展開していきます。しかもそのサービスのほとんどが無料で誰でも使えるように。
ほんの十数年前まで、私たちはメールを自分のパソコンに受信して返信していました。だから、外出していたり、いつもと違うパソコンを使っているだけでメールを見ることも返事することもできませんでした。しかしGmailが登場すると、メールのやりとりはすべてウェブ上で完結するようになり、パソコンが違っても、外出先でも、スマホ1つあればメールの操作はできるようになっています。
もし道に迷ってしまった時、もし見知らぬ土地に旅に出た時、これまでは分厚い地図帳を持ち運んでいました。しかしGoogleMapの登場で地図帳を見る機会はめっきり減りました。方向音痴の人で、地図を見ても現在地自体がわからなかった人も、スマホでGoogleMapを見れば、現在地だけでなく、今向いている方向がどっちなのかさえも分かります。
他にもオフィスソフトであるWordやExcelと同等の機能を持つGoogleドキュメントやGoogleスプレッドシート。今ではパソコン上にデータを保存して保管するよりも、GoogleDriveのようなクラウドストレージにすべてのデータを預けてしまうほうが、安全で効率的な仕事ができるようにもなりました。
これらすべてのサービスは、ウェブ上に散らばっていた人々の情報をひとつの場所に集めて、分類し、再利用できるようにするためにGoogleが開発し公開したものです。それは一体何のために再利用されるのでしょうか?
答えは簡単です。人工知能のために利用されるのです。
Googleは、人と同じように考える検索エンジンを提供することが私たちの生活にもっとも役立つと信じているのですから。
新時代のバベルの塔。私たちはまたひとつになれるのか。
インターネットの誕生から、WEBサイトがあちらこちらで立ち上がり、Googleがウェブ上の情報をすべて集めている。
そんな歴史を振り返ってみた時に、私はついバベルの塔を思い浮かべてしまいました。
旧約聖書の中に神話として書かれているバベルの塔。その中ではまだ世界の人々は同じ言語を操り、不自由なくコミュニケーションをとることができていた。そうして人々が協力して点にまで届くような塔を作り上げようとしていたところ、神の怒りに触れ人々の言葉は乱され、人々は世界に散り散りとなった。
ときは現代となり、インターネットという道が世界中で整備され、WEBには様々な街ができました。そして人々(の情報)はまた一つの場所に集まり、時間も場所も飛び越えたコミュニケーションをとることで新たなバベルの塔が築かれているように思えます。
また歴史はつながり、人工知能の実現へ大きく帆を進めていることも分かりました。
インターネットの原型である銀河間ネットワークを構想したリック・ライダーは脳科学者でした。
WEBを発明したティム・バーナーズ=リーの両親は、コンピュータの生みの親であるチューリングと一緒に研究をしていました。
そしてGoogle創業者2人の担当教授は、初期の人工知能開発の権威でした。
人と同じように考える機械を作ることを目指したコンピュータは、様々な人間模様を経てインターネットという重要なピースを埋めることにもつながっていたのです。
そして、僕たちのポケットを占領したあれが登場します。
以上で連載企画『AIの歴史を紐解く』の第三章はおわりです。
年代的にも一気に現代の話へとなったので、懐かしい言葉がでてきた方もいるのではないでしょうか?次回はさらに時代は進み、ついに今の私たちの生活に欠かせないあのデバイスが登場します。
次回、『【第四章】60億人が知識を共有する最後のワンピースは8月中にお届けできるよう鋭意執筆中です。お楽しみに!
【序章】今さらだけどAI(人工知能)が怖いから歴史を紐解いてみる
【第一章】人間は、心を作れるのか?コンピュータの生みの親たち
【第二章】方針転換!人間を賢くしてくれる機械を作ろう
【第三章】誕生、サイバー空間に漂う巨大な頭脳 ←今ココ
【第四章】60億人が知識を共有する最後のワンピース
【第五章】ついに姿を現す人工知能。彼らは人間の味方か、それとも
【最終章】20年後の近い未来。そして人類は何から解放されるのか
